TensorFlow api-based neural net.
Contents
TensorFlow api-based neural net.#
In this workbook we build a neural network to predict survival. The two common frameworks used for neural networks (as of 2020) are TensorFlow and PyTorch. Both are excellent frameworks. TensorFlow frequently requires fewer lines of code, but PyTorch is more natively Python in its syntax, and also allows for easier debugging as the model may be interrupted, with a breakpoint, and debugged as necessary. This makes PyTorch particularly suitable for research and experimentation. A disadvantage of using PyTorch is that, compared with TensorFlow, there are fewer training materials and examples available.
Here we use ‘keras’ which is integrated into TensorFlow and makes it simpler and faster to build TensorFlow models.
Both TensorFlow and PyTorch allow the neural network to be trained on a GPU, which is beneficial for large neural networks (especially those processing image, sound or free-text data). In order to lever the benefits of GPU (which perform many calculations simultaneously), data is grouped into batches. These batches are presented to the CPU in a single object called a Tensor (a multi-dimensional array).
To install TensorFlow as a new environment in Anaconda type the following from a terminal
conda create -n tensorflow tensorflow && conda install -n tensorflow scikit-learn pandas matplotlib
Or PIP install with:
pip install --upgrade pip
pip install tensorflow
The latest release of TensorFlow supports CPU and GPU, If using an older installation then use tensorflow-gpu in place of tensorflow to install a gpu-capable version of TensorFlow.
Then from Anaconda Navigator, select the TensorFlow environment.
There are two versions of this workbook. This version uses a simpler form of constructing the neural network. The alternative version uses an api-based method which offers some more flexibility (but at the cost of a little simplicity). It is recommended to work through both methods.
It is not the intention here to describe neural networks in any detail, but rather give some introductory code to using a neural network for a classification problem. For an introduction to neural networks see: https://en.wikipedia.org/wiki/Artificial_neural_network
The code for PyTorch here keeps all calculations on the CPU rather than passing to a GPU (if you have one). Running neural networks on CPUs is fine for structured data such as our Titanic data. GPUs come in to their own for unstructured data like images, sound clips, or free text.
The training process of a neural network consists of three general phases which are repeated across all the data. All of the data is passed through the network multiple times (the number of iterations, which may be as few as 3-5 or may be 100+). The three phases are:
Pass training X data to the network and predict y
Calculate the ‘loss’ (error) between the predicted and observed (actual) values of y
Adjust the network a little (as defined by the learning rate) so that the error is reduced. The correction of the network is performed by PyTorch or TensorFlow using a technique called ‘back-propagation’.
The learning is repeated until maximum accuracy is achieved (but keep an eye on accuracy of test data as well as training data as the network may develop significant over-fitting to training data unless steps are taken to offset the potential for over-fitting, such as use of ‘drop-out’ layers described below).
Note: Neural Networks are most often used for complex unstructured data. For structured data, other techniques, such as Random Forest,s may frequently be preferred.
# Turn warnings off to keep notebook tidy
import warnings
warnings.filterwarnings("ignore")
Load modules#
import numpy as np
import pandas as pd
# sklearn for pre-processing
from sklearn.preprocessing import MinMaxScaler
from sklearn.model_selection import StratifiedKFold
# TensorFlow api model
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam
from tensorflow.keras import backend as K
from tensorflow.keras.losses import binary_crossentropy
2022-11-21 08:54:57.333109: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.10.1
Download data if not previously downloaded#
download_required = True
if download_required:
# Download processed data:
address = 'https://raw.githubusercontent.com/MichaelAllen1966/' + \
'1804_python_healthcare/master/titanic/data/processed_data.csv'
data = pd.read_csv(address)
# Create a data subfolder if one does not already exist
import os
data_directory ='./data/'
if not os.path.exists(data_directory):
os.makedirs(data_directory)
# Save data
data.to_csv(data_directory + 'processed_data.csv', index=False)
Define function to calculate accuracy measurements#
import numpy as np
def calculate_accuracy(observed, predicted):
"""
Calculates a range of accuracy scores from observed and predicted classes.
Takes two list or NumPy arrays (observed class values, and predicted class
values), and returns a dictionary of results.
1) observed positive rate: proportion of observed cases that are +ve
2) Predicted positive rate: proportion of predicted cases that are +ve
3) observed negative rate: proportion of observed cases that are -ve
4) Predicted negative rate: proportion of predicted cases that are -ve
5) accuracy: proportion of predicted results that are correct
6) precision: proportion of predicted +ve that are correct
7) recall: proportion of true +ve correctly identified
8) f1: harmonic mean of precision and recall
9) sensitivity: Same as recall
10) specificity: Proportion of true -ve identified:
11) positive likelihood: increased probability of true +ve if test +ve
12) negative likelihood: reduced probability of true +ve if test -ve
13) false positive rate: proportion of false +ves in true -ve patients
14) false negative rate: proportion of false -ves in true +ve patients
15) true positive rate: Same as recall
16) true negative rate: Same as specificity
17) positive predictive value: chance of true +ve if test +ve
18) negative predictive value: chance of true -ve if test -ve
"""
# Converts list to NumPy arrays
if type(observed) == list:
observed = np.array(observed)
if type(predicted) == list:
predicted = np.array(predicted)
# Calculate accuracy scores
observed_positives = observed == 1
observed_negatives = observed == 0
predicted_positives = predicted == 1
predicted_negatives = predicted == 0
true_positives = (predicted_positives == 1) & (observed_positives == 1)
false_positives = (predicted_positives == 1) & (observed_positives == 0)
true_negatives = (predicted_negatives == 1) & (observed_negatives == 1)
false_negatives = (predicted_negatives == 1) & (observed_negatives == 0)
accuracy = np.mean(predicted == observed)
precision = (np.sum(true_positives) /
(np.sum(true_positives) + np.sum(false_positives)))
recall = np.sum(true_positives) / np.sum(observed_positives)
sensitivity = recall
f1 = 2 * ((precision * recall) / (precision + recall))
specificity = np.sum(true_negatives) / np.sum(observed_negatives)
positive_likelihood = sensitivity / (1 - specificity)
negative_likelihood = (1 - sensitivity) / specificity
false_positive_rate = 1 - specificity
false_negative_rate = 1 - sensitivity
true_positive_rate = sensitivity
true_negative_rate = specificity
positive_predictive_value = (np.sum(true_positives) /
(np.sum(true_positives) + np.sum(false_positives)))
negative_predictive_value = (np.sum(true_negatives) /
(np.sum(true_negatives) + np.sum(false_negatives)))
# Create dictionary for results, and add results
results = dict()
results['observed_positive_rate'] = np.mean(observed_positives)
results['observed_negative_rate'] = np.mean(observed_negatives)
results['predicted_positive_rate'] = np.mean(predicted_positives)
results['predicted_negative_rate'] = np.mean(predicted_negatives)
results['accuracy'] = accuracy
results['precision'] = precision
results['recall'] = recall
results['f1'] = f1
results['sensitivity'] = sensitivity
results['specificity'] = specificity
results['positive_likelihood'] = positive_likelihood
results['negative_likelihood'] = negative_likelihood
results['false_positive_rate'] = false_positive_rate
results['false_negative_rate'] = false_negative_rate
results['true_positive_rate'] = true_positive_rate
results['true_negative_rate'] = true_negative_rate
results['positive_predictive_value'] = positive_predictive_value
results['negative_predictive_value'] = negative_predictive_value
return results
Define function to scale data#
In neural networks it is common to to scale input data 0-1 rather than use standardisation (subtracting mean and dividing by standard deviation) of each feature).
def scale_data(X_train, X_test):
"""Scale data 0-1 based on min and max in training set"""
# Initialise a new scaling object for normalising input data
sc = MinMaxScaler()
# Set up the scaler just on the training set
sc.fit(X_train)
# Apply the scaler to the training and test sets
train_sc = sc.transform(X_train)
test_sc = sc.transform(X_test)
return train_sc, test_sc
Load data#
data = pd.read_csv('data/processed_data.csv')
# Make all data 'float' type
data = data.astype(float)
data.drop('PassengerId', inplace=True, axis=1)
X = data.drop('Survived',axis=1) # X = all 'data' except the 'survived' column
y = data['Survived'] # y = 'survived' column from 'data'
# Convert to NumPy as required for k-fold splits
X_np = X.values
y_np = y.values
Set up neural net#
Here we use the api-based method to set up a TensorFlow neural network. This method allows us to more flexibly define the inputs for each layer, rather than assuming there is a simple sequence as with the Sequential method.
We will put construction of the neural net into a separate function.
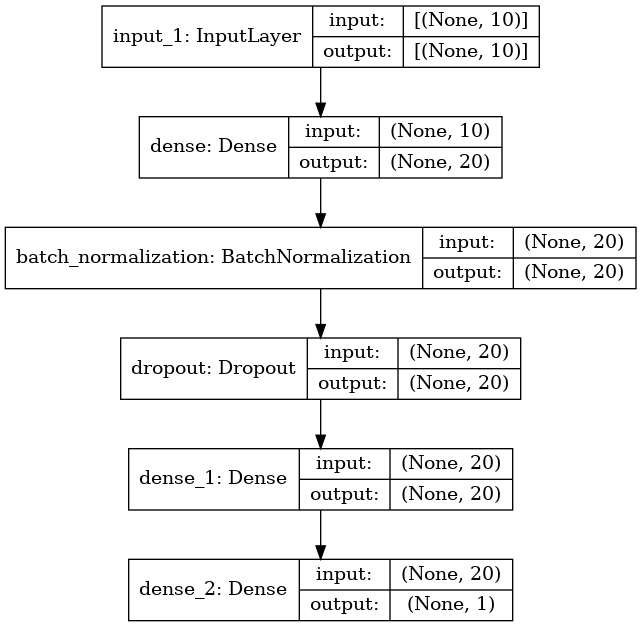
The neural net is a relatively simple network. The inputs are connected to two hidden layers (of 240 and 50 nodes) before being connected to two output nodes corresponding to each class (died and survived). It also contains some useful additions (batch normalisation and dropout) as described below.
The layers of the network are:
An input layer (which does need to be defined)
A linear fully-connected (dense) layer.This is defined by the number of inputs (the number of input features) and the number of nodes/outputs. Each node will receive the values of all the inputs (which will either be the feature data for the input layer, or the outputs from the previous layer - so that if the previous layer had 10 nodes, then each node of the current layer would have 10 inputs, one from each node of the previous layer). It is a linear layer because the output of the node at this point is a linear function of the dot product of the weights and input values. We will expand out feature data set up to twice the number of input features. ral network. Negative input values are set to zero. Positive input values are left unchanged.
A batch normalisation layer. This is not usually used for small models, but can increase the speed of training for larger models. It is added here as an example of how to include it (in large models all dense layers would be followed by a batch normalisation layer). The layer definition includes the number of inputs to normalise.
A dropout layer. This layer randomly sets outputs from the preceding layer to zero during training (a different set of outputs is zeroed for each training iteration). This helps prevent over-fitting of the model to the training data. Typically between 0.1 and 0.3 outputs are set to zero (p=0.1 means 10% of outputs are set to zero).
A second linear fully connected layer (again twice the number of input features). This is again followed by batch normalisation, dropout and ReLU activation layers.
A final fully connected linear layer of one nodes (more nodes could be used for more classes, in which case use softmax activation and categorical_crossentropy in the loss function). The output of the net is the probability of surviving (usually a probability of >= 0.5 will be classes as ‘survived’).
def make_net(number_features, learning_rate=0.003):
# Clear Tensorflow
K.clear_session()
# Define layers
inputs = layers.Input(shape=number_features)
dense_1 = layers.Dense(number_features * 2, activation='relu')(inputs)
norm_1 = layers.BatchNormalization()(dense_1)
dropout_1 = layers.Dropout(0.25)(norm_1)
dense_2 = layers.Dense(number_features * 2, activation='relu')(dropout_1)
outputs = layers.Dense(1, activation='sigmoid')(dense_2)
net = Model(inputs, outputs)
# Compiling model
opt = Adam(lr=learning_rate)
net.compile(loss='binary_crossentropy',
optimizer=opt,
metrics=['accuracy'])
return net
Show summary of the model structure#
Here we will create a model with 10 input features and show the structure of the model as atable and as a graph.
model = make_net(10)
model.summary()
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 10)] 0
_________________________________________________________________
dense (Dense) (None, 20) 220
_________________________________________________________________
batch_normalization (BatchNo (None, 20) 80
_________________________________________________________________
dropout (Dropout) (None, 20) 0
_________________________________________________________________
dense_1 (Dense) (None, 20) 420
_________________________________________________________________
dense_2 (Dense) (None, 1) 21
=================================================================
Total params: 741
Trainable params: 701
Non-trainable params: 40
_________________________________________________________________
2022-11-21 08:54:58.431875: I tensorflow/compiler/jit/xla_cpu_device.cc:41] Not creating XLA devices, tf_xla_enable_xla_devices not set
2022-11-21 08:54:58.432493: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcuda.so.1
2022-11-21 08:54:58.445854: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:941] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2022-11-21 08:54:58.445952: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1720] Found device 0 with properties:
pciBusID: 0000:01:00.0 name: NVIDIA GeForce RTX 3050 Ti Laptop GPU computeCapability: 8.6
coreClock: 1.035GHz coreCount: 20 deviceMemorySize: 3.82GiB deviceMemoryBandwidth: 163.94GiB/s
2022-11-21 08:54:58.445973: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.10.1
2022-11-21 08:54:58.446719: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcublas.so.10
2022-11-21 08:54:58.446772: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcublasLt.so.10
2022-11-21 08:54:58.447653: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcufft.so.10
2022-11-21 08:54:58.447863: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcurand.so.10
2022-11-21 08:54:58.448566: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcusolver.so.10
2022-11-21 08:54:58.448899: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcusparse.so.10
2022-11-21 08:54:58.450847: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudnn.so.7
2022-11-21 08:54:58.450954: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:941] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2022-11-21 08:54:58.451065: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:941] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2022-11-21 08:54:58.451115: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1862] Adding visible gpu devices: 0
2022-11-21 08:54:58.451722: I tensorflow/core/platform/cpu_feature_guard.cc:142] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: SSE4.1 SSE4.2 AVX AVX2 FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2022-11-21 08:54:58.455159: I tensorflow/compiler/jit/xla_gpu_device.cc:99] Not creating XLA devices, tf_xla_enable_xla_devices not set
2022-11-21 08:54:58.455417: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:941] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2022-11-21 08:54:58.455617: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1720] Found device 0 with properties:
pciBusID: 0000:01:00.0 name: NVIDIA GeForce RTX 3050 Ti Laptop GPU computeCapability: 8.6
coreClock: 1.035GHz coreCount: 20 deviceMemorySize: 3.82GiB deviceMemoryBandwidth: 163.94GiB/s
2022-11-21 08:54:58.455672: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.10.1
2022-11-21 08:54:58.455697: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcublas.so.10
2022-11-21 08:54:58.455714: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcublasLt.so.10
2022-11-21 08:54:58.455733: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcufft.so.10
2022-11-21 08:54:58.455748: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcurand.so.10
2022-11-21 08:54:58.455765: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcusolver.so.10
2022-11-21 08:54:58.455780: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcusparse.so.10
2022-11-21 08:54:58.455796: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudnn.so.7
2022-11-21 08:54:58.455868: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:941] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2022-11-21 08:54:58.456010: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:941] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2022-11-21 08:54:58.456083: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1862] Adding visible gpu devices: 0
2022-11-21 08:54:58.456110: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcudart.so.10.1
2022-11-21 08:54:59.329867: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1261] Device interconnect StreamExecutor with strength 1 edge matrix:
2022-11-21 08:54:59.329881: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1267] 0
2022-11-21 08:54:59.329884: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1280] 0: N
2022-11-21 08:54:59.330039: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:941] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2022-11-21 08:54:59.330142: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:941] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2022-11-21 08:54:59.330202: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:941] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2022-11-21 08:54:59.330258: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1406] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 3376 MB memory) -> physical GPU (device: 0, name: NVIDIA GeForce RTX 3050 Ti Laptop GPU, pci bus id: 0000:01:00.0, compute capability: 8.6)
# If necessary pip or conda install pydot and graphviz
keras.utils.plot_model(model, "titanic_tf_model.png", show_shapes=True)
Run the model with k-fold validation#
# Set up lists to hold results
training_acc_results = []
test_acc_results = []
# Set up splits
skf = StratifiedKFold(n_splits = 5)
skf.get_n_splits(X, y)
# Loop through the k-fold splits
k_counter = 0
for train_index, test_index in skf.split(X_np, y_np):
k_counter +=1
print('K_fold {}'.format(k_counter))
# Get X and Y train/test
X_train, X_test = X_np[train_index], X_np[test_index]
y_train, y_test = y_np[train_index], y_np[test_index]
# Scale X data
X_train_sc, X_test_sc = scale_data(X_train, X_test)
# Define network
number_features = X_train_sc.shape[1]
model = make_net(number_features)
### Train model
model.fit(X_train_sc,
y_train,
epochs=150,
batch_size=32,
verbose=0)
### Test model (print results for each k-fold iteration)
probability = model.predict(X_train_sc)
y_pred_train = probability >= 0.5
y_pred_train = y_pred_train.flatten()
accuracy_train = np.mean(y_pred_train == y_train)
training_acc_results.append(accuracy_train)
probability = model.predict(X_test_sc)
y_pred_test = probability >= 0.5
y_pred_test = y_pred_test.flatten()
accuracy_test = np.mean(y_pred_test == y_test)
test_acc_results.append(accuracy_test)
K_fold 1
2022-11-21 08:54:59.692599: I tensorflow/compiler/mlir/mlir_graph_optimization_pass.cc:116] None of the MLIR optimization passes are enabled (registered 2)
2022-11-21 08:54:59.692874: I tensorflow/core/platform/profile_utils/cpu_utils.cc:112] CPU Frequency: 2918400000 Hz
2022-11-21 08:54:59.968047: I tensorflow/stream_executor/platform/default/dso_loader.cc:49] Successfully opened dynamic library libcublas.so.10
K_fold 2
K_fold 3
K_fold 4
K_fold 5
Show training and test results#
# Show individual accuracies on training data
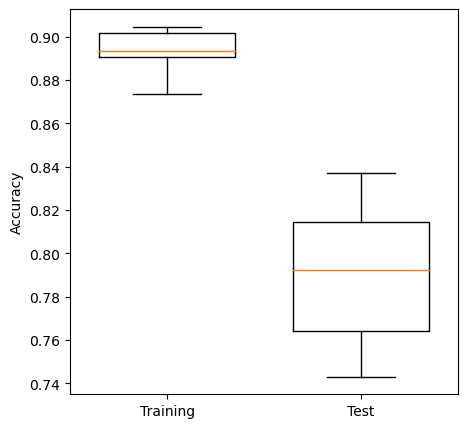
training_acc_results
[0.901685393258427,
0.9046283309957924,
0.8906030855539971,
0.8934081346423562,
0.8737727910238429]
# Show individual accuracies on test data
test_acc_results
[0.7430167597765364,
0.7921348314606742,
0.8146067415730337,
0.7640449438202247,
0.8370786516853933]
# Get mean results
mean_training = np.mean(training_acc_results)
mean_test = np.mean(test_acc_results)
# Display each to three decimal places
print ('{0:.3f}, {1:.3}'.format(mean_training,mean_test))
0.893, 0.79
Plot results: Box Plot#
Box plots show median (orange line), the second and third quartiles (the box), the range (excluding outliers), and any outliers as ‘whisker’ points. Outliers, by convention, are conisiered to be any points outside of the quartiles +/- 1.5 times the interquartile range. The limit for outliers may be changed using the optional whis argument in the boxplot.
Medians tend to be an easy reliable guide to the centre of a distribution (i.e. look at the medians to see whether a fit is improving or not, but also look at the box plot to see how much variability there is).
Test sets tend to be more variable in their accuracy measures. Can you think why?
import matplotlib.pyplot as plt
%matplotlib inline
# Set up X data
x_for_box = [training_acc_results, test_acc_results]
# Set up X labels
labels = ['Training', 'Test']
# Set up figure
fig = plt.figure(figsize=(5,5))
# Add subplot (can be used to define multiple plots in same figure)
ax1 = fig.add_subplot(111)
# Define Box Plot (`widths` is optional)
ax1.boxplot(x_for_box,
widths=0.7,
whis=100)
# Set X and Y labels
ax1.set_xticklabels(labels)
ax1.set_ylabel('Accuracy')
# Show plot
plt.show()
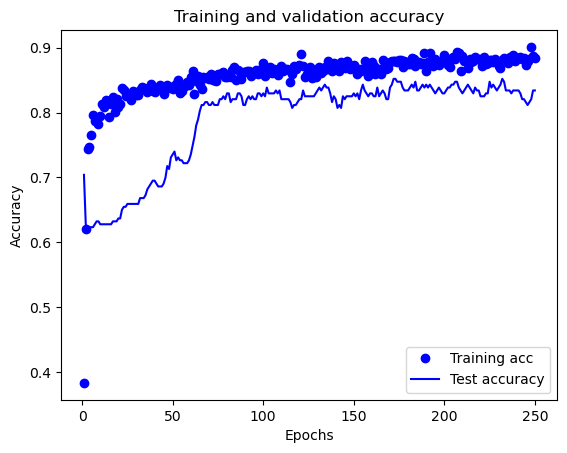
Using TensorFlow’s training history#
TensorFlow can track the history of training, enabling us to examine performance against training and test sets over time. Here we will use the same model as above, but without k-fold validation and with history tracking.
from sklearn.model_selection import train_test_split
# Split into training and test sets
X_train, X_test, y_train, y_test = train_test_split(
X_np, y_np, test_size = 0.25)
# Scale data
X_train_sc, X_test_sc = scale_data(X_train, X_test)
# Define network
number_features = X_train_sc.shape[1]
model_2 = make_net(number_features)
# Train model
history = model_2.fit(X_train_sc,
y_train,
epochs=250,
batch_size=512,
validation_data=(X_test_sc, y_test),
verbose=0)
history is a dictionary containing data collected during training. Let’s take a look at the keys in this dictionary (these are the metrics monitored during training):
history_dict = history.history
history_dict.keys()
dict_keys(['loss', 'accuracy', 'val_loss', 'val_accuracy'])
Plot training history:
import matplotlib.pyplot as plt
%matplotlib inline
acc_values = history_dict['accuracy']
val_acc_values = history_dict['val_accuracy']
epochs = range(1, len(acc_values) + 1)
plt.plot(epochs, acc_values, 'bo', label='Training acc')
plt.plot(epochs, val_acc_values, 'b', label='Test accuracy')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
Getting model weights#
Here we show how weights for a layer can be extracted from the model if required.
hidden1 = model.layers[1]
hidden1.name
'dense'
weights, biases = hidden1.get_weights() # Biases are not used in this model
weights.shape
(24, 48)
weights
array([[-0.25289223, 0.0089573 , -0.27491435, ..., 0.0426338 ,
-0.03406185, 0.34181413],
[-0.11349136, 0.22068281, -0.5531101 , ..., -0.3987295 ,
-0.35948583, -0.14833109],
[ 0.24423613, 0.21060422, -0.6320418 , ..., 0.55794257,
0.76699865, 0.36112458],
...,
[ 0.14193854, -0.08188624, 0.1892125 , ..., 0.14804359,
0.10430929, -0.17817934],
[ 0.2838201 , -0.07639708, -0.2817484 , ..., -0.19457579,
-0.23896515, 0.15054658],
[-0.06116315, -0.15682226, -0.22222073, ..., -0.18413118,
-0.22550723, 0.06565644]], dtype=float32)
Evaluating model#
If a test set is not used to evaluate in training, or if there is an independnent test set, evaluation may be quickly performed using the evaluate method.
model_2.evaluate(X_test_sc, y_test)
7/7 [==============================] - 0s 1ms/step - loss: 0.5215 - accuracy: 0.8341
[0.5215047597885132, 0.834080696105957]