Optimising machine learning models with Optuna
Contents
Optimising machine learning models with Optuna#
A model hyperparamter is a setting in the model that is set prior to learning from a data set. It may affect how well the model learns from data. Examples include the level of regularisation in a logistic regression model, or the number of trees in a random forest model
Many machine learning models have many hyperparameters that may be changed, and each may have many different possible levels to choose from. How do you find the best combination (though most machine learning packages come with sensible defaults which may already give optimal or close to optimal results).
Optuna (optuna.org) is a machine learning model optimizer that may be used on any machine learning model type. Optuna uses heuristic (searching) algorithms to find the best combination of model hyperparameters. It also allows more traditional alternatives to heuristic algorithms, such as grid search and random search.
To install optuna (if not installed as part of the Titanic environment’: pip install optuna. The visualisations require plotly (pip install plotly).
Validation and testing when optimising hyperparameters#
A model hyperparamter is a setting in the model that is set prior to learning from a data set. It may affect how well the model learns from data. Examples include the level of regularisation in a logistic regression model, or the number of trees in a random forest model
Many machine learning models have many hyperparameters that may be changed, and each may have many different possible levels to choose from. How do you find the best combination (though most machine learning packages come with sensible defaults which may already give optimal or close to optimal results).
When optimising model hyperparameters, we use only the training set of data, and test independently with a test set not used to optimise those hyperparameters. This avoids reporting a spuriously high accuracy level due to over-fitting of model hyperparameters to the training set.
During optimisation we create new k-fold train/test splits from the training set. The model hyperparameters are then trained on the average accuracy of these new k-fold test splits. Here we will use simple accuracy (the proportion of tets instances correctly classified), but you may choose to use other measures such as receiver operator characteristic curve AUC, or mean squared error (for a regression model).

import optuna
import numpy as np
import pandas as pd
from pprint import pprint
import sklearn.ensemble
import sklearn.model_selection
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
# The following are needed only to show Optuna images in a Jupyter Book
from IPython.display import Image, display
# Turn off optuna progress reporting
optuna.logging.set_verbosity(optuna.logging.WARNING)
# To save images you will also need to `pip install kaleido`
# Make images folder if it does not already exist
import os
if not os.path.exists('images'):
os.makedirs('images')
Optimize a simple problem#
Find x that minmises (x-2)^2
(x=2 minimises output)
def objective(trial):
# Set study parameter to vary
x = trial.suggest_float('x', -10, 10)
# Return value for optimisation
return (x - 2) ** 2
study = optuna.create_study()
study.optimize(objective, n_trials=100)
# Run optimisation (default is to minimise objective)
study.best_params
{'x': 2.003453991305076}
Download Titanic data#
download_required = True
if download_required:
# Download processed data:
address = 'https://raw.githubusercontent.com/MichaelAllen1966/' + \
'1804_python_healthcare/master/titanic/data/processed_data.csv'
data = pd.read_csv(address)
# Create a data subfolder if one does not already exist
import os
data_directory ='./data/'
if not os.path.exists(data_directory):
os.makedirs(data_directory)
# Save data
data.to_csv(data_directory + 'processed_data.csv', index=False)
data = pd.read_csv('data/processed_data.csv')
# Make all data 'float' type
data = data.astype(float)
# Drop Passengerid (axis=1 indicates we are removing a column rather than a row)
data.drop('PassengerId', inplace=True, axis=1)
Divide into X (features) and y (labels)#
# Split data into two DataFrames
X_df = data.drop('Survived',axis=1)
y_df = data['Survived']
# Convert DataFrames to NumPy arrays
X_all = X_df.values
y_all = y_df.values
Create train and test (hold-out) sets#
X_train, X_test, y_train, y_test = train_test_split(X_all, y_all, random_state=42, test_size=0.25)
Optimize Hyperparameters#
Define a simple scikit-learn model#
We start with a simple random forest model to classify Titanic survivors vs. non-survivors. We define a function called objective that encapsulates the whole training process and outputs the accuracy of the model.
def objective():
# Define model
model = sklearn.ensemble.RandomForestClassifier(
n_estimators=5, max_depth=3)
# Assess accuracy with sklearn.model_selection.cross_val_score
accuracy = sklearn.model_selection.cross_val_score(
model, X_train, y_train, n_jobs=-1, cv=3).mean()
return accuracy
print(f'Accuracy in optimisation cross-validation: {objective():0.3f}')
Accuracy in optimisation cross-validation: 0.752
Optimize hyperparameters of the model#
The hyperparameters of the above algorithm are n_estimators and max_depth for which we can try different values to see if the model accuracy can be improved.
def objective(trial):
# Set Optuna trial parameters and ranges
n_estimators = trial.suggest_int('n_estimators', 2, 60)
max_depth = int(trial.suggest_float('max_depth', 1, 32, log=True))
# Set up model
model = sklearn.ensemble.RandomForestClassifier(
n_estimators=n_estimators, max_depth=max_depth)
# Assess accuracy with sklearn.model_selection.cross_val_score
accuracy = sklearn.model_selection.cross_val_score(
model, X_train, y_train, n_jobs=-1, cv=3).mean()
return accuracy
# Set up Optuna study - we need to specifiy that we wish to maximise objective
study = optuna.create_study(direction='maximize')
# Run optimisation
study.optimize(objective, n_trials=100)
# Get best model run
trial = study.best_trial
print(f'Accuracy: {trial.value:0.3f}')
print(f'Best hyperparameters: {trial.params}')
Accuracy: 0.816
Best hyperparameters: {'n_estimators': 34, 'max_depth': 12.594235950405126}
Note that max_depth is a float. This is because we asked for it to be varied over a log scale, and that requires a float. The actual max_depth used is the corresponding integer of that flaot.
Passing arguments to a trial#
In the above example we passed onlyy a trial object to Optuna. The data to use was defined outside of the function and is avilable through Python’s ability of functions to access data defined in the main program.
We may wish to pass arguments (such as the data to use) to Optuna. To do that requires defining the objective as a Lambda function as below.
def objective(trial, X, y):
# Set Optuna trial parameters and ranges
n_estimators = trial.suggest_int('n_estimators', 2, 60)
max_depth = int(trial.suggest_float('max_depth', 1, 32, log=True))
# Set up model
model = sklearn.ensemble.RandomForestClassifier(
n_estimators=n_estimators, max_depth=max_depth)
# Assess accuracy with sklearn.model_selection.cross_val_score
accuracy = sklearn.model_selection.cross_val_score(
model, X, y, n_jobs=-1, cv=3).mean()
return accuracy
# Wrap the objective inside a lambda function with included arguments
func = lambda trial: objective(trial, X_train, y_train)
# Set up Optuna study - we need to specifiy that we wish to maximise objective
study = optuna.create_study(direction='maximize')
# Run optimisation using the lambda function
study.optimize(func, n_trials=100)
# Get best model run
trial = study.best_trial
print(f'Accuracy: {trial.value:0.3f}')
print(f'Best hyperparameters: {trial.params}')
Accuracy: 0.817
Best hyperparameters: {'n_estimators': 35, 'max_depth': 8.077515056973361}
Checking model accuracy on the hold-out test set#
After optimising the hyperparamters we should test accuracy on the hold out test set (we will only do that here, and not later in the notebook to keep the notebook shorter - but you shoudl always follow model hyperparamter optimisation with testing on an independent test set).
# Get hyperparamters from best model
n_estimators = study.best_trial.params['n_estimators']
max_depth = int(study.best_trial.params['max_depth'])
# Set up model
model = sklearn.ensemble.RandomForestClassifier(
n_estimators=n_estimators, max_depth=max_depth, random_state=42)
# Fit model
model.fit(X_train,y_train)
# Test accuracy
y_pred_test = model.predict(X_test)
accuracy_test = np.mean(y_pred_test == y_test)
print(f'Accuracy on test set: {accuracy_test:0.3f}')
Accuracy on test set: 0.812
Building in conditional if statements#
It is possible to condition hyperparameters using Python if statements. We can for instance include another classifier, a logistic regression classifier, in our hyperparameter optimsation and define hyperparameters specific to the random forest model and the logistic regression models.
def objective(trial):
# All Optuna to choose classifier (Random Forest or logistic regression)
classifier = trial.suggest_categorical(
'classifier', ['RandomForest', 'LogisticRegression'])
# If Random Forest set Optuna trial parameters for random forest
if classifier == 'RandomForest':
n_estimators = trial.suggest_int('n_estimators', 2, 60)
max_depth = int(trial.suggest_float('max_depth', 1, 32, log=True))
# Set up model
model = sklearn.ensemble.RandomForestClassifier(
n_estimators=n_estimators, max_depth=max_depth)
# Otherwise set Optuna trial parameters for logistic regression
else:
c = trial.suggest_float('lr_c', 1e-10, 1e10, log=True)
# Set up model
model = LogisticRegression(C=c)
# Run selected model
accuracy = sklearn.model_selection.cross_val_score(
model, X_train, y_train, n_jobs=-1, cv=3).mean()
return accuracy
# Set up Optuna study
study = optuna.create_study(direction='maximize')
# Run optimisation
study.optimize(objective, n_trials=100)
# Get best model run
trial = study.best_trial
print(f'Accuracy: {trial.value:0.3f}')
print(f'Best hyperparameters: {trial.params}')
Accuracy: 0.817
Best hyperparameters: {'classifier': 'RandomForest', 'n_estimators': 25, 'max_depth': 7.35702553078595}
Plotting the study#
Plotting the optimization history of the study.
fig = optuna.visualization.plot_optimization_history(study)
# To display fig in an ordinary notebook use `fig.show()`
# The following is needed only to display the image in an online Jupyter Book
# Or is you wish to save the figure
filename = './images/temp.jpg'
fig.write_image(filename)
display(Image(filename))
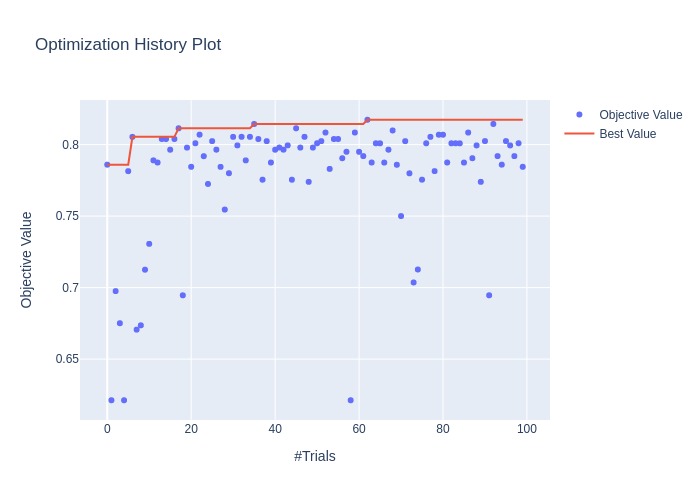
Plotting the accuracies for each hyperparameter for each trial.
fig = optuna.visualization.plot_slice(study)
# To display fig in an orinary norebook use `fig.show()`
# The following is needed only to display the image in an online Jupyter Book
# Or is you wish to save the figure
filename = './images/temp.jpg'
fig.write_image(filename)
display(Image(filename))
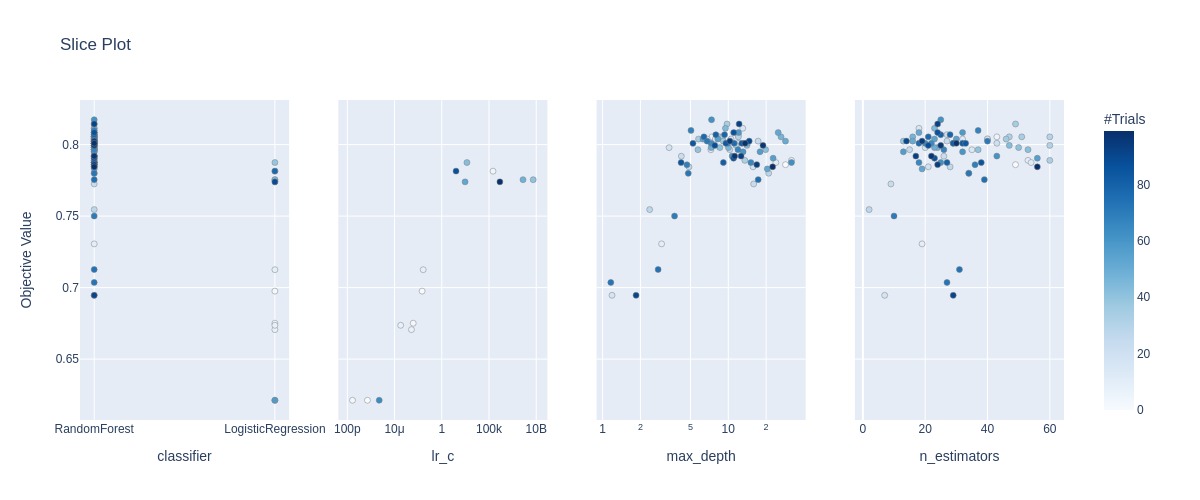
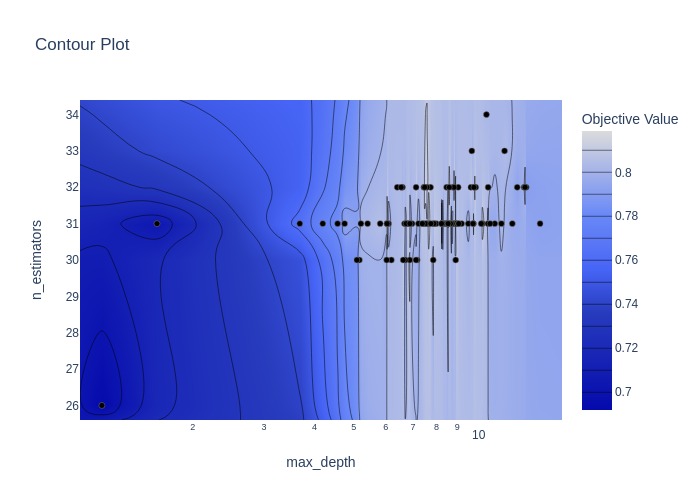
Plotting the accuracy surface for the hyperparameters involved in the random forest model.
fig = optuna.visualization.plot_contour(study, params=['n_estimators', 'max_depth'])
# To display fig in an orinary norebook use `fig.show()`
# The following is needed only to display the image in an online Jupyter Book
# Or is you wish to save the figure
filename = './images/temp.jpg'
fig.write_image(filename)
display(Image(filename))
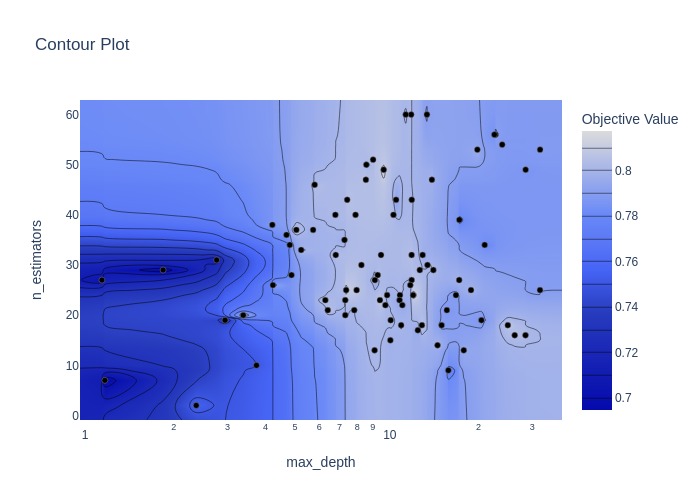
Switching sampling Algorithms#
Samplers continually narrow down the search space using the records of suggested parameter values and evaluated objective values,
leading to an optimal search space which giving off parameters leading to better objective values.
More detailed explanation of how samplers suggest parameters is in :class:optuna.samplers.BaseSampler.
Optuna provides the following sampling algorithms:
Tree-structured Parzen Estimator algorithm implemented in :class:
optuna.samplers.TPESamplerCMA-ES (Covariance matrix adaptation evolution strategy) based algorithm implemented in :class:
optuna.samplers.CmaEsSamplerGrid Search implemented in :class:
optuna.samplers.GridSamplerRandom Search implemented in :class:
optuna.samplers.RandomSampler
The default sampler is :class:optuna.samplers.TPESampler.
We can define an alternative sampler when we define the study. Here we use a CMA-ES sampler.
def objective(trial):
# Set Optuna trial parameters and ranges
n_estimators = trial.suggest_int('n_estimators', 2, 60)
max_depth = int(trial.suggest_float('max_depth', 1, 32, log=True))
# Set up model
clf = sklearn.ensemble.RandomForestClassifier(
n_estimators=n_estimators, max_depth=max_depth)
# Assess accuracy with sklearn.model_selection.cross_val_score
accuracy = sklearn.model_selection.cross_val_score(
clf, X_train, y_train, n_jobs=-1, cv=3).mean()
return accuracy
# Set up Optuna study
study = optuna.create_study(direction='maximize',
sampler=optuna.samplers.CmaEsSampler())
# Run optimisation
study.optimize(objective, n_trials=100)
# Get best model run
trial = study.best_trial
print(f'Accuracy: {trial.value:0.3f}')
print(f'Best hyperparameters: {trial.params}')
Accuracy: 0.819
Best hyperparameters: {'n_estimators': 31, 'max_depth': 6.042386622291878}
fig = optuna.visualization.plot_optimization_history(study)
# To display fig in an orinary norebook use `fig.show()`
# The following is needed only to display the image in an online Jupyter Book
# Or is you wish to save the figure
filename = './images/temp.jpg'
fig.write_image(filename)
display(Image(filename))
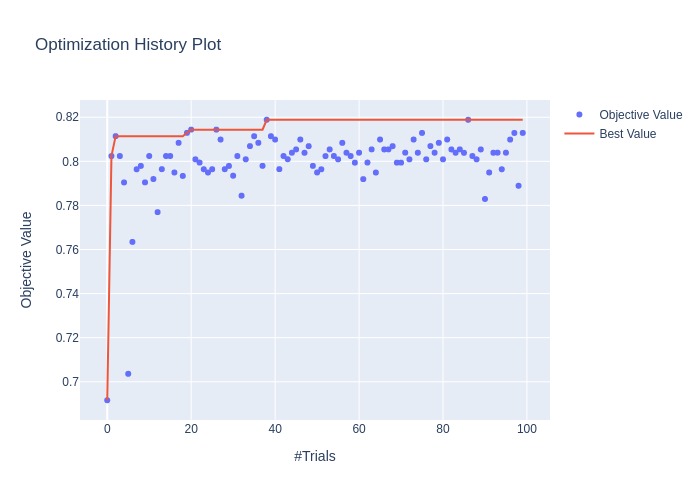
fig = optuna.visualization.plot_contour(study, params=['n_estimators', 'max_depth'])
# To display fig in an orinary norebook use `fig.show()`
# The following is needed only to display the image in an online Jupyter Book
# Or is you wish to save the figure
filename = './images/temp.jpg'
fig.write_image(filename)
display(Image(filename))
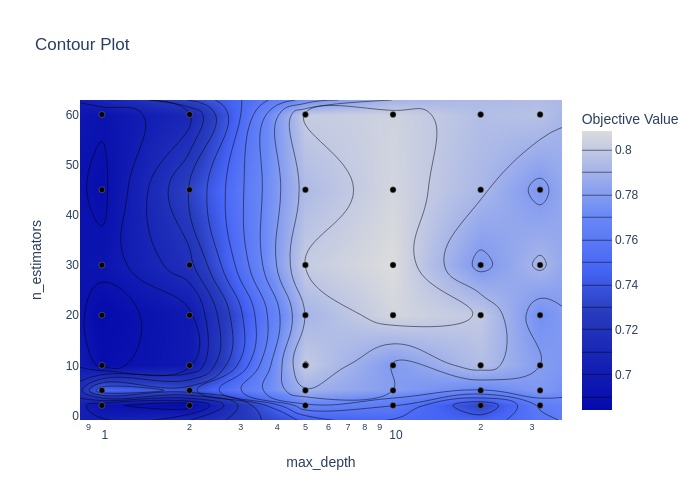
Grid search#
With grid search, the defined search space over-rides the trial suggestions in the objective. Grid seach can be effective when there are not too many hyperparamters and options to chose from. A broad grid search may be followed by a narrower one.
def objective(trial):
# Set Optuna trial parameters and ranges
n_estimators = trial.suggest_int('n_estimators', 2, 60)
max_depth = int(trial.suggest_float('max_depth', 1, 32, log=True))
# Set up model
model = sklearn.ensemble.RandomForestClassifier(
n_estimators=n_estimators, max_depth=max_depth)
# Assess accuracy with sklearn.model_selection.cross_val_score
accuracy = sklearn.model_selection.cross_val_score(
model, X_train, y_train, n_jobs=-1, cv=3).mean()
return accuracy
# Define search space: this will over-ride the suggestions in the objective
# function, but must be within the limits set by the suggestions
search_space = {
"n_estimators": [2, 5, 10, 20, 30, 45, 60],
"max_depth": [1, 2, 5, 10, 20, 32]}
# Set up Optuna study
study = optuna.create_study(direction='maximize',
sampler=optuna.samplers.GridSampler(search_space))
# Run optimisation
study.optimize(objective, n_trials=100)
# Get best model run
trial = study.best_trial
print(f'Accuracy: {trial.value:0.3f}')
print(f'Best hyperparameters: {trial.params}')
Accuracy: 0.808
Best hyperparameters: {'n_estimators': 30, 'max_depth': 10}
fig = optuna.visualization.plot_contour(study, params=['n_estimators', 'max_depth'])
# To display fig in an orinary norebook use `fig.show()`
# The following is needed only to display the image in an online Jupyter Book
# Or is you wish to save the figure
filename = './images/temp.jpg'
fig.write_image(filename)
display(Image(filename))
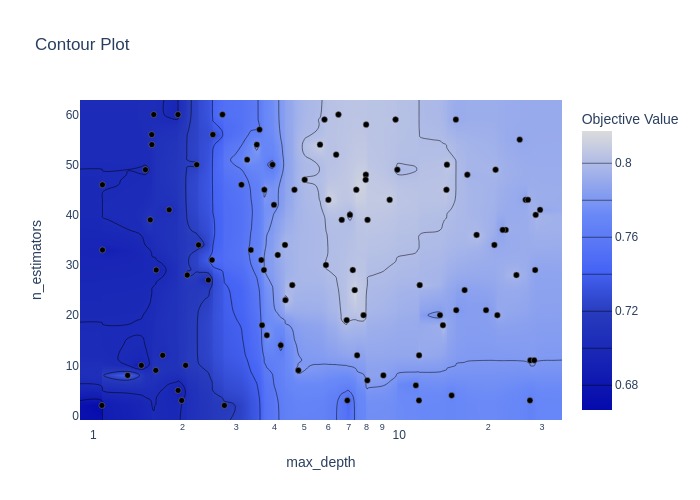
Random search#
Random search may be a ueful starting point for exploring hyperparamter optimisation. It may be followed by a grid search or one of the heuristic methods.
def objective(trial):
# Set Optuna trial parameters and ranges
n_estimators = trial.suggest_int('n_estimators', 2, 60)
max_depth = int(trial.suggest_float('max_depth', 1, 32, log=True))
# Set up model
model = sklearn.ensemble.RandomForestClassifier(
n_estimators=n_estimators, max_depth=max_depth)
# Assess accuracy with sklearn.model_selection.cross_val_score
accuracy = sklearn.model_selection.cross_val_score(
model, X_train, y_train, n_jobs=-1, cv=3).mean()
return accuracy
# Set up Optuna study
study = optuna.create_study(direction='maximize',
sampler=optuna.samplers.RandomSampler())
# Run optimisation
study.optimize(objective, n_trials=100)
# Get best model run
trial = study.best_trial
print(f'Accuracy: {trial.value:0.3f}')
print(f'Best hyperparameters: {trial.params}')
Accuracy: 0.817
Best hyperparameters: {'n_estimators': 25, 'max_depth': 7.31826690278078}
fig = optuna.visualization.plot_contour(study, params=['n_estimators', 'max_depth'])
# To display fig in an orinary norebook use `fig.show()`
# The following is needed only to display the image in an online Jupyter Book
# Or is you wish to save the figure
filename = './images/temp.jpg'
fig.write_image(filename)
display(Image(filename))
What hyperparamters may be changed?#
Each model type will have different hyperparameters that may be tuned. Here we have used only a limited set for illustration.
Below are examples fo showing available hyperparameters for SciKit-Learn’s random forest and logistic regression classifiers.
rf = sklearn.ensemble.RandomForestClassifier()
print('Parameters currently in use:\n')
pprint(rf.get_params())
Parameters currently in use:
{'bootstrap': True,
'ccp_alpha': 0.0,
'class_weight': None,
'criterion': 'gini',
'max_depth': None,
'max_features': 'auto',
'max_leaf_nodes': None,
'max_samples': None,
'min_impurity_decrease': 0.0,
'min_samples_leaf': 1,
'min_samples_split': 2,
'min_weight_fraction_leaf': 0.0,
'n_estimators': 100,
'n_jobs': None,
'oob_score': False,
'random_state': None,
'verbose': 0,
'warm_start': False}
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
print('Parameters currently in use:\n')
pprint(lr.get_params())
Parameters currently in use:
{'C': 1.0,
'class_weight': None,
'dual': False,
'fit_intercept': True,
'intercept_scaling': 1,
'l1_ratio': None,
'max_iter': 100,
'multi_class': 'auto',
'n_jobs': None,
'penalty': 'l2',
'random_state': None,
'solver': 'lbfgs',
'tol': 0.0001,
'verbose': 0,
'warm_start': False}